Preprocess Waveforms
This step preprocesses waveforms using the preprocessing.py module and saves the resulting Stream objects to disk in a workflow-aware folder structure.
For local/SDS sources, waveforms are read from the archive via
DataAvailability records. For FDSN/EIDA sources, waveforms are fetched from
the remote service using get_waveforms_bulk and optionally cached as raw
files (fdsn_keep_raw=Y) before preprocessing.
Configuration Parameters
preprocess.preprocess_components: Components to preprocess:Zonly is enough for ZZ Cross-Correlation (CC) jobs, whileE,N,Zis needed if e.g. SC jobs are desired. (default=E,N,Z)preprocess.remove_response: Remove instrument response (default=N)global.response_path: Instrument correction file(s) location (path relative to db.ini), defaults to ‘./inventory’, i.e. a subfolder in the current project folder. All files in that folder will be parsed. (default=inventory)global.fdsn_keep_raw: Y: cache raw fetched waveforms to _output/raw/<date>/ for re-use by other preprocess configsets without re-fetching (default=N)global.hpc: Is MSNoise going to run on an HPC? (default=N)
Waveform Pre-processing
Pairs are first split and a station list is created. The database is then
queried to get file paths. For each station, all files potentially containing
data for the day are opened. The traces are then merged and split, to obtain
the most continuous chunks possible. The different chunks are then demeaned,
tapered and merged again to a 1-day long trace. If a chunk is not aligned
on the sampling grid (that is, start at a integer times the sample spacing in s)
, the chunk is phase-shifted in the frequency domain. This requires tapering and
fft/ifft. If the gap between two chunks is small, compared to
preprocess_max_gap, the gap is filled with interpolated values.
Larger gaps will not be filled with interpolated values.
Each 1-day long trace is then high-passed (at preprocess_highpass Hz), then
if needed, low-passed (at preprocess_lowpass Hz) and decimated/downsampled.
Decimation/Downsampling are configurable (resampling_method) and users are
advised testing Decimate. One advantage of Downsampling over Decimation is that
it is able to downsample the data by any factor, not only integer factors.
Downsampling is achieved with the ObsPy Lanczos resampler which we tested
against the old scikits.samplerate.
If configured, each 1-day long trace is corrected for its instrument response. Currently, only dataless seed and inventory XML are supported.
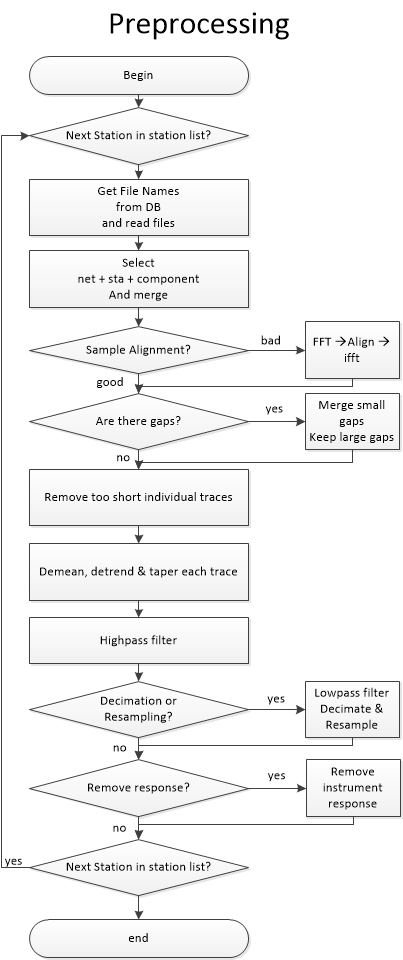
As from MSNoise 1.5, the preprocessing routine is separated from the compute_cc and can be used by plugins with their own parameters. The routine returns a Stream object containing all the traces for all the stations/components.
- msnoise.s02_preprocessing.main(loglevel='INFO')
Main preprocessing workflow function.
Dispatches to the local-archive or FDSN/EIDA fetch path depending on the station’s DataSource URI scheme, then preprocesses and writes per-station output files.